Company oriented product development project courses are important last parts in the information technology bachelor’s degree studies. MediaTek Wireless Finland Oy offered three students an opportunity to dive into the world of generative AI and the results were positive.
Each information technology student has three company-oriented product development projects in their curriculum and these projects serve as the final studies before the thesis. The primary objective of the three projects is to give students a chance to practice project working methods as a team member in companies solving real problems and learning at the same. Additionally, these projects serve as a bridge from academia to professional employment, complementing practical training and the bachelor’s thesis. Every year in autumn information technology teachers collaborate with companies who are interested in offering project topics to students. Companies then present their project ideas to students, who apply for the projects they find interesting. The companies select participants from the applicants and the project work usually starts in March.
We (Antti-Jussi Niku, Moufida Dkhili EP Alakulju, and Yinan Li) applied to the project offered by MediaTek Wireless Finland Oy, which is a long-standing project partner with Oulu University of Applied Sciences (Oamk). Their topic this year was from the field of generative AI. We managed to get selected to the project and got to design and implement a market-leading AI implementation for 3GPP (Third Generation Partnership Project) Change Request (CR) analytics application. The 3GPP organization is an standards organization, which develops telecommunication standards for mobile communications.
The goal – design and develop 3GPP change request analytics application
The project aimed to define and develop a market-leading 3GPP CR analytics application, specifically an MVP (Minimum Viable Product).
The project objectives as defined in the project start meeting:
- Chatbot for 3GPP Queries: This feature will assist users in understanding specific topics related to 3GPP.
- Summarizer for 3GPP Specifications: It will summarize the content of 3GPP documents.
- Release Comparator for Specification Versions: This function will highlight changes between different releases.
- Reverse CR Search: Users can find CRs (Change Requests) that introduce modifications to specified lines, chapters, or topics.
After two weeks of researching the 3GPP specification and CR documents, interviewing end users to clarify the actual use cases, and analyzing the requirements mentioned in the kick-start meeting, the project objective was then translated as developing a 3GPP chat bot using Retrieval-augmented Generation (RAG).
The target outcomes include delivering a functional MVP of the RAG application, gaining insights into the cost-efficient realization of such applications, and documenting findings during the development.
The project was scheduled from the 5th week to the 23rd week of 2024. The final delivery is split into two major milestones to deliver the Alpha and Beta versions, along with documentation produced along the way that covers development, research, and observations. The team created subgoals to be accomplished in 2-week sprints, aiming to reach the target milestones planned for the end of each 6-week phase.
A final report is presented in the last week (week 18). Research and planning continued throughout the entire project. The schedule is illustrated in figure 1.
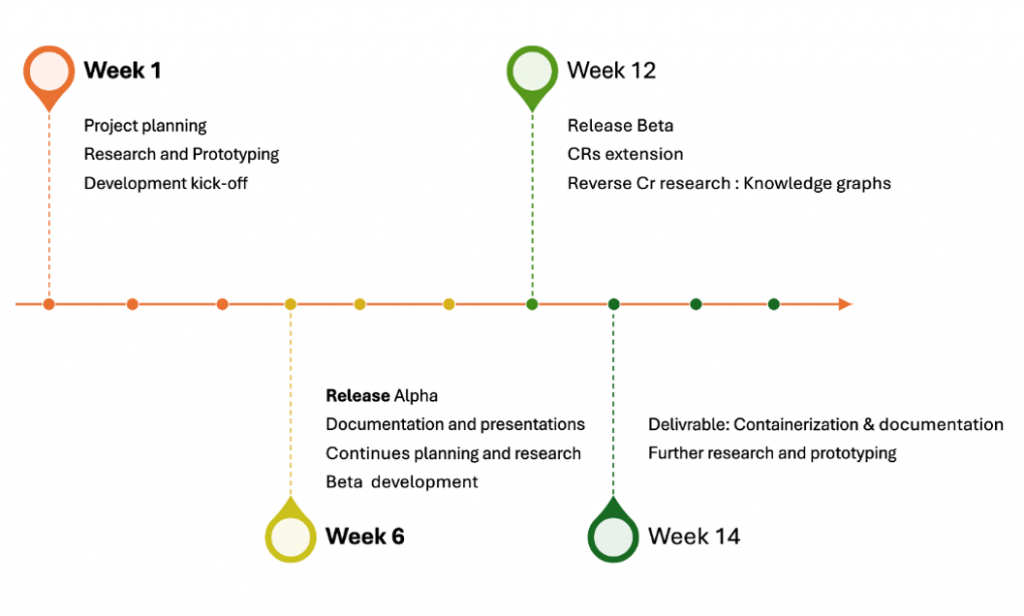
In the 6th week, the project reached the Alpha release stage, signifying the completion of the initial version of the application as planned. The Alpha version and findings about Large Language Model (LLM) and RAG were presented to different stakeholders internally as part of the post-release activities spread over the weeks following the first release.
In parallel to the post-release presentations, the finalization of the Beta version was completed by the end of week 12. This involved enhancing the performance of the Alpha model in terms of cost and accuracy.
From week 12 to week 18, the project focused on including the CR tool and introducing a knowledge graph as a solution to visualize and enhance the understanding of how CRs affect the 3GPP. This phase also included transferring the project and providing documentation to MediaTek. (Image 1.)

Project results
Design of retrieval augmented generation application
Retrieval Augmented Generation (RAG) is the process of optimizing the output of a generative large language model by referencing an authoritative knowledge base outside of its training data sources before generating a response.
Despite our concise and straightforward definition, the papers from Cornell University served as the foundation for our implementation [2] [3]. They provided the groundwork for our project, offering an in-depth introduction to RAG, its paradigms and architecture that we will address in the upcoming sections.
RAG expands the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base, addressing privacy concerns by residing within the organization’s premises and can be isolated from external access. It also mitigates bias and output inaccuracies, by enforcing references to the source for answer generation and without requiring model retraining.
The core of a RAG system is leveraging external knowledge sources, often in the form of vast text databases or knowledge bases such as websites, to augment the generation capabilities of neural models. Instead of relying solely on the information stored during the training phase, RAG systems can dynamically pull information from these external sources when generating responses or completing tasks in a two-step process: a retrieval step and generation step that works as follows. When presented with a query or prompt, the system first retrieves relevant documents or passages from an external database.
This retrieval is based on similarity metrics, a measure that ensures that the most pertinent information is fetched. After retrieval, the model uses the fetched documents or passages as context to generate a coherent and contextually relevant response.
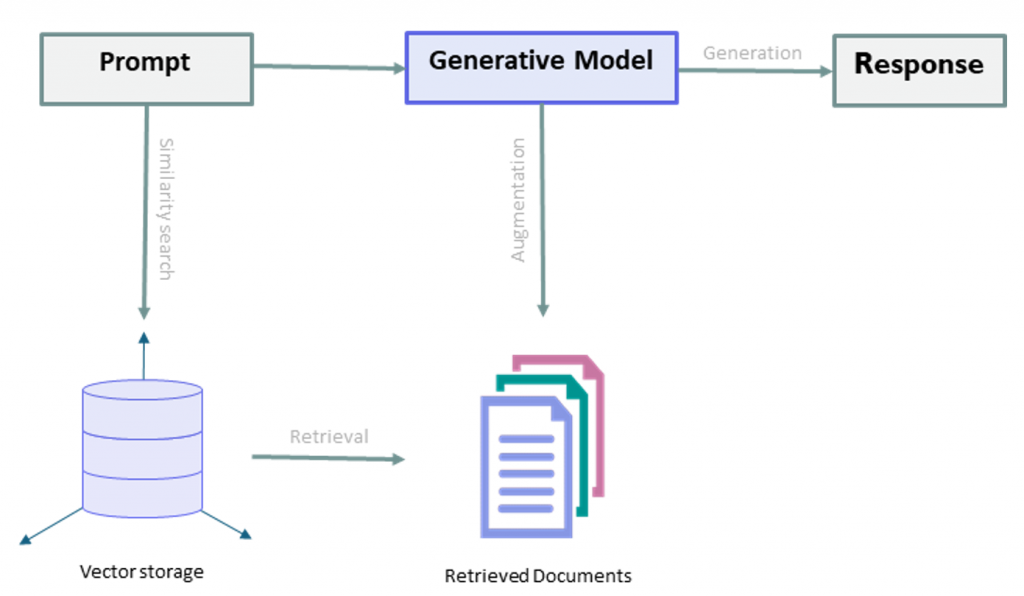
Figure 2 presents the general design of our implementation of the RAG application. It describes the high-level RAG process. The user initiates the process by prompting a question. The query then triggers a search algorithm, retrieving a reference source from the data source. This retrieved information serves as a reference for the generative language model, enabling it to generate a customized and referenced response to the initial prompt.
Data pre-processing
Data preprocessing aims to transform raw documents from their original format into a project-friendly structure. This facilitates subsequent actions, such as database insertion and ensures portability — essential for scenarios like deploying a project where the application runs on a virtual machine.
The project format was decided to be a JavaScript Object Notation (JSON) file that holds a list of text chunks (pieces) metadata about the chunks (parent section, parent paragraph) and document metadata.
Text chunking refers to the process of breaking down unstructured text data into meaningful units. These units can be phrases, sentences, or other coherent segments. Most language models have limitations due to token limits. These constraints impact the amount of text that can be processed in a single compilation. However, chunking techniques allow us to work within these limitations while maintaining meaningful context.
The 3GPP and change request documents adhere to strict formatting rules. They are typically in Microsoft Word DOCX format, featuring a unified layout, tables of content, and well-defined headers and text sections.
The consistent structure at the paragraph level allows us to identify independent topics. Consequently, the list of content and its related paragraphs can serve as explicit separators. These separators help isolate coherent text information that can address specific user queries.
DOCX files are complex, containing both textual content and layout information. To create a script capable of chunking each document based on the list of content, we faced a choice:
- Extensible Markup Language (XML) Level: Work directly with the XML structure of the document.
- Conversion to Markdown: Convert the DOCX files to Markdown using tools like Pandoc.
In our use case, we opted to convert DOCX files to Markdown. Markdown headers (e.g., #, ##, ###, etc.) served as explicit separators, allowing us to create document chunks. Additionally, we kept track of the parent paragraph for each chunk.
Some paragraphs within the documents were lengthy. To address this, we implemented a condition: If a parent paragraph exceeds a certain context size, we split the chunk into smaller sub-chunks. This dynamic chunking prioritizes the paragraph-level separation and when a paragraph is too long, it dynamically switches to fixed-size chunking. Each chunk retains metadata indicating which paragraph and section of the document it belongs to.
Summarizing the results from the data preprocessing phase, our approach utilizes consistent paragraph structures, Markdown headers, and dynamic chunking to organize and extract relevant information from 3GPP documents. The resulting chunks strike a balance: they are neither too short nor too lengthy, providing coherent answers to specific user queries while fitting within the context size commonly used for embedding and generative models.
Embeddings
Major cloud computing providers such as Amazon Web Services (AWS) and Google, as well as LLM companies, offer comprehensive walkthroughs and fairly good documentation on embeddings. They provide guidance on how to use them and when to apply them as solutions, which assists their user base in getting started with embeddings. This availability of alternative references was particularly helpful for us, as research papers often delve deeply into specialized and complex topics [4] [5].
Research papers, when navigated carefully, offer valuable insights into the theory behind document embeddings. This theoretical understanding later supported our observations and reasoning when determining how to work with text [6].
Text embeddings are numerical vectors that represent human language. These vectors capture the meaning of words, sentences, or even entire documents. Stored embeddings enable tasks such as semantic search and text similarity analysis, allowing computers to effectively understand and work with textual data.
When working with vectors in a vector space, we handle quantities that possess both magnitude and direction. These vectors represent data points in a multi-dimensional space. Embeddings, in turn, serve as compact representations of objects or concepts within this multi-dimensional space. The dimensions of these embeddings correspond to the number of features used to represent each object in the embedding space, capturing various aspects or characteristics.
Floating-Point embeddings are represented as continuous real numbers (floating points). They offer high precision and capture fine-grained semantic information. They are commonly used in natural language processing tasks like word embeddings (e.g., Word2Vec, GloVe). However, their precision comes at the cost of computational complexity.
Binary Embeddings use a compact representation (usually binary codes) for efficiency. They sacrifice some precision to achieve faster processing. Examples include locality-sensitive hashing (LSH) and binary code representations. They are ideal for large-scale similarity search or recommendation systems.
Embedding models
Embedding models are algorithms trained to encapsulate information into dense representations in a multi-dimensional space. In our case it is the algorithms that will give it the text chunks as text strings and it measures the relatedness and return embeddings, a vector (list) of floating-point numbers. The distance between two vectors measures their relatedness. Small distances suggest high relatedness and large distances suggest low relatedness.
Embeddings are commonly used for:
- Search (where results are ranked by relevance to a query string)
- Clustering (where text strings are grouped by similarity)
- Recommendations (where items with related text strings are recommended)
- Anomaly detection (where outliers with little relatedness are identified)
- Diversity measurement (where similarity distributions are analyzed)
- Classification (where text strings are classified by their most similar label)
Document embeddings is a demanding topic in terms of complexity. As Information Technology students, the challenge was to make sure not to get lost and confused by this topic while selecting the appropriate level of depth helped us define the necessary level of understanding required for the project. We prioritized grasping essential concepts without getting overwhelmed by the highly specialized details.
In the practical part of this stage, we employ a script that iterates through our project’s JSON files. The purpose is to send the original text chunks to the OpenAI embeddings Application Programming Interface (API) endpoint, with the text-embedding-3-large as the designated engine. This engine has a maximum context size of 8191 tokens and 3072 dimensions. Our choice is grounded in the ease of use (thanks to APIs) and the decision to opt for a relatively large context size and rich dimensionality.
The response we receive consists of a list of vectors corresponding to each sent text chunk. The script then inserts these embeddings back into the same JSON file for use in subsequent steps.
Storage concepts and storage strategy
At this point, we have the JSON data from each subject document, which includes the original text chunks, relevant metadata, and embeddings.
In the prototyping and experimental context, it’s already possible to perform similarity searches directly from the file. While this approach is acceptable for gathering observations and exploring search metrics, it has limitations. For a more flexible and scalable implementation, setting up a database designed specifically for efficient storage and retrieval of vectors is the recommended approach.
These vector databases come with built-in search engines and allow efficient indexing of vectors on a massive scale. In a vector database, a collection is analogous to a table in a traditional database. For our 3GPP documentation, each collection can host a subset of specifications relevant to specific aspects, such as the Radio Access Network (RAN) collection, Core Network (CN) collection, and User Equipment (UE) collection.
We’ve chosen to set up a standalone Milvus vector database. Milvus is an open-source solution with well-maintained documentation that offered us full guidance and getting started, using and extending our use of Milvus database [7].
In Milvus there is a limit on how much data can be handled at once (insertion, loading, search, etc.). By default, Milvus uses MySQL/SQLite database for metadata management, which typically occurs in the background without requiring manual intervention. However, in our case, we assessed that extending this implementation to support vector storage alongside relational storage would improve the overall storage strategy, creating a hybrid solution.
The concept behind this hybrid approach involves leveraging the capabilities of a relational database to preserve the relationship between “pieces” of retrieved data that we previously collected in the JSON version of each document. This metadata enables us to implement a storage system that replicates the structure of the parent file containing the retrieved chunk. Additionally, it captures the chunk’s relation to other content and files within the same collection which later can support retrieval.
Retrievals and generation
Semantic search, also known as similarity search, involves searching for objects or concepts similar to a given query based on their meaning. The results of this search are the retrievals, and the operation itself is called retrieval.
As per Milvus documentation [8], when working with floating-point embeddings, the Milvus search engine provides three metric options for similarity searching:
- Euclidean Distance (L2): This metric measures the length of a segment connecting two points in the embedding space. It is useful for finding nearest neighbors based on geometric distance. However, it does not consider the angle between vectors.
- Inner Product (IP): The IP metric utilizes both magnitude and angle. It filters results based on the importance or complexity of sentences, ensuring that the retrieved sentences are semantically related to the query.
- Cosine Similarity (COSINE): This metric measures how similar two sets of vectors are by calculating the cosine of the angle between them. It is commonly used for semantic similarity tasks and takes both magnitude and direction into account.
Here’s how the semantic search function operates:
- Input: The function takes the user’s query as a parameter.
- Embedding: It calls the embed function, which uses the OpenAI embedding engine (specifically, text-embedding-3-large) to generate query embeddings.
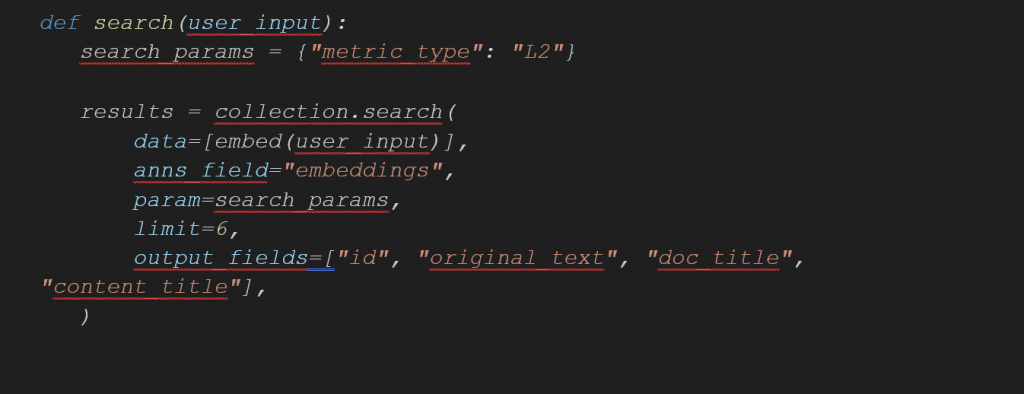
- Similarity Metric: The function uses the Euclidean distance similarity metric (specified as “metric_type: L2” in the snippet). This metric calculates the Euclidean distance between the embeddings from the stored chunks in the database and the query embeddings.
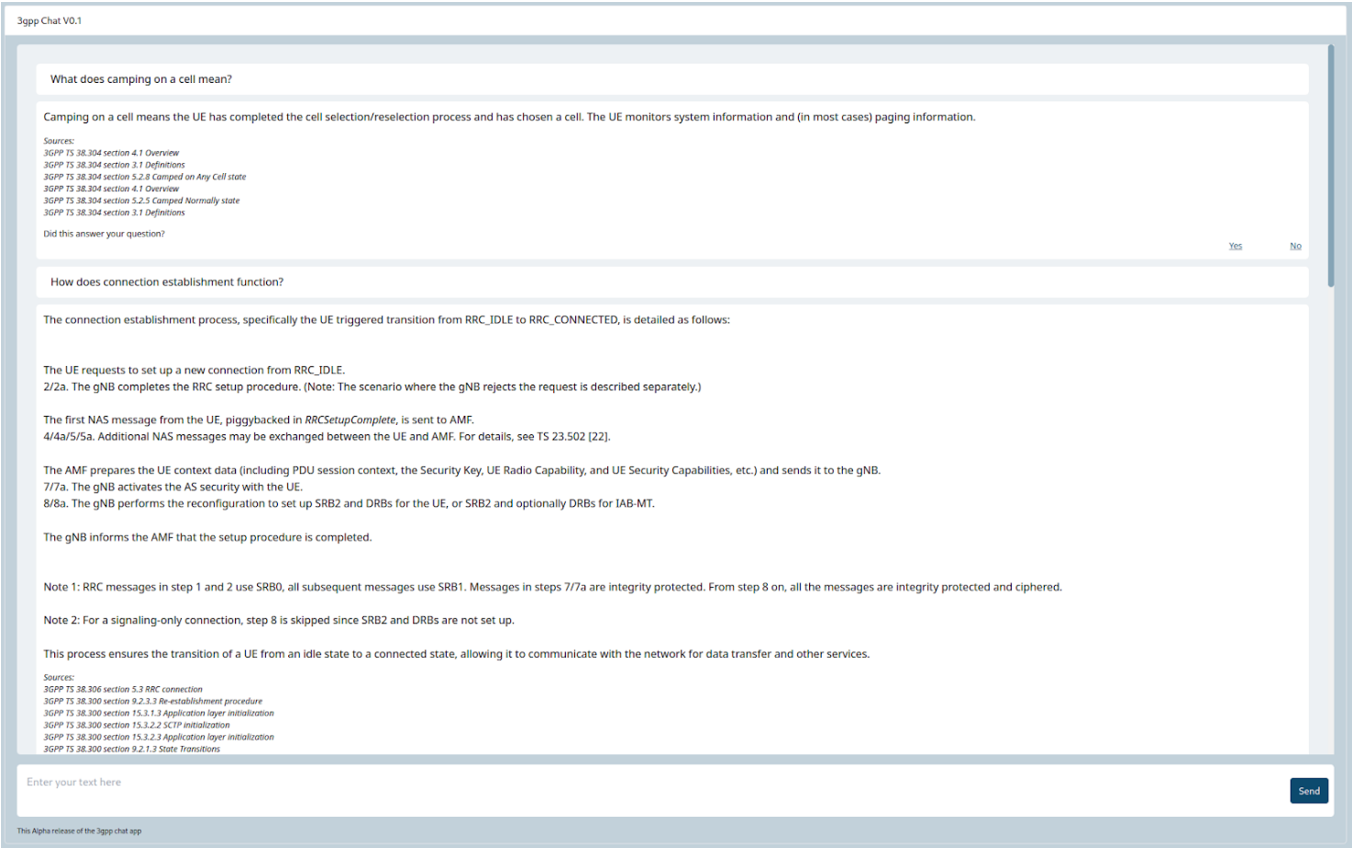
- Search Results: Finally, the search function shown in image 2, compiles a list of best hits. Each hit includes relevant information associated with the retrieved chunks, such as the original text, document title, content title, and other relevant metadata. The hits are sorted based on their similarity scores.
Once we have retrieved the relevant documents for the query and returned them in a list, we are ready to augment the generation process.
For the generation we are using OpenAI generative model engine gpt-4-turbo-preview. From here, it’s a straightforward procedure:
- The retrieved items are parsed from the list.
- These items are then included in the system prompt given to the generative model. They serve as references for the model to use while generating answers.
- Finally, a response is generated based on the user’s original query, using these provided references.
The response, along with the references used, is communicated back to the user. As shown in the image 3, the generative model is instructed in the prompt system to refrain from answering if the references provided do not contain an answer to the user’s question.
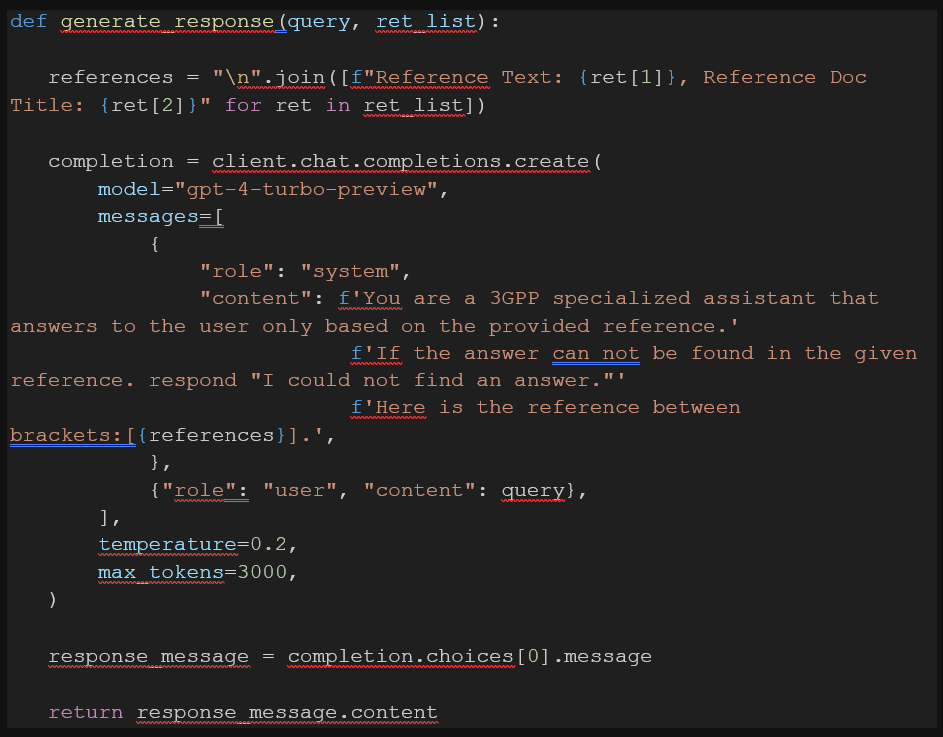
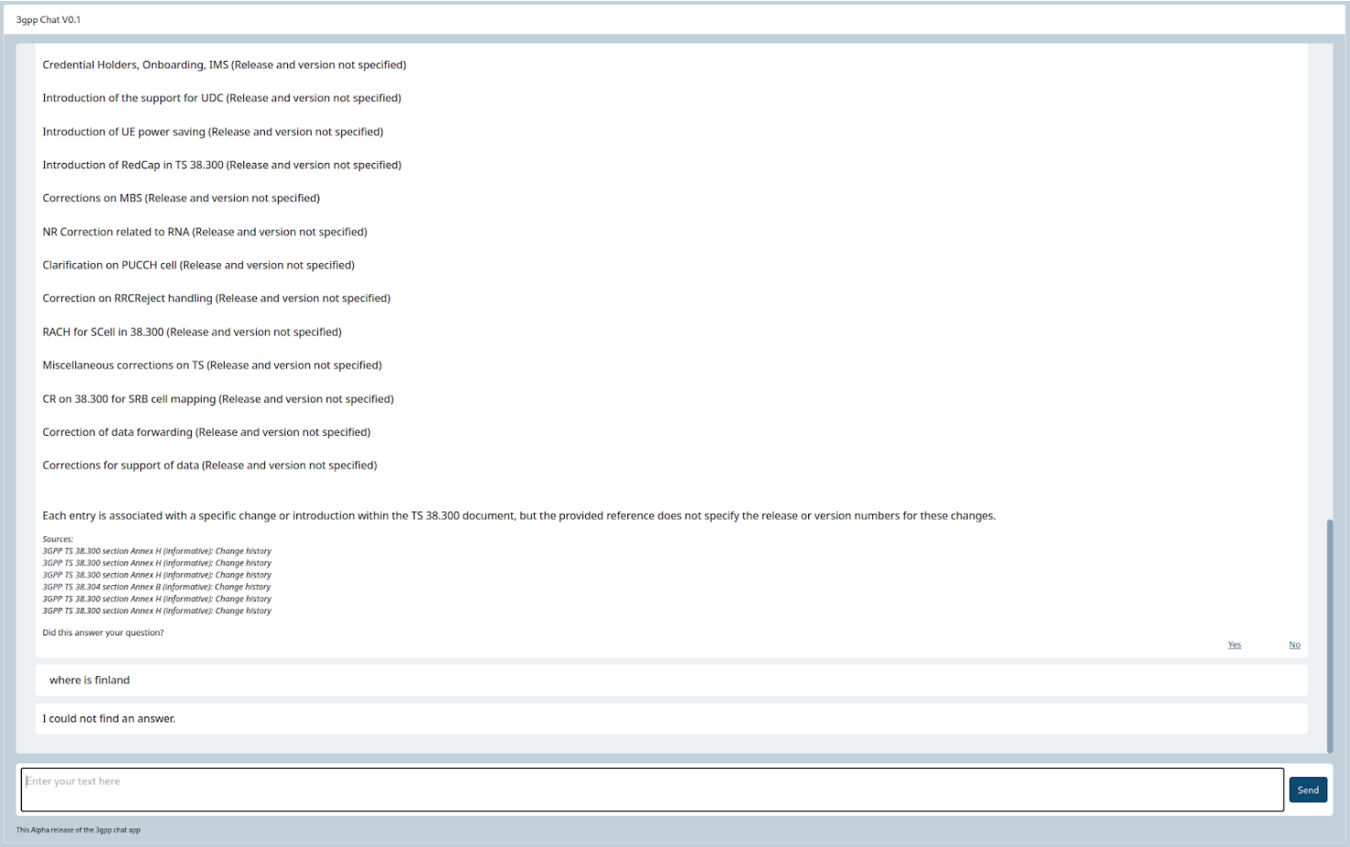
Images 4 and 5 convey that the model successfully follows these instructions. The system provides the answer to the user’s query along with links to the references used to answer the question, which the user can inspect if needed. Additionally, the system refrains from answering questions that are not covered by the references in the database, regardless of whether the generative model has seen the information in the training data or not.
We can then conclude that our project has succeeded in addressing hallucination by relying on authoritative sources of knowledge and limiting response generation to the information provided as references from the retrieval process.
However, this approach places pressure on the accuracy and quality of the retrieval we implement, the generative model is strictly instructed to refrain from answering if the answer for the user query could not be found in the provided references, getting an answer depends mainly on accurately retrieving the document that has the answer. This sets the stage for the need to enhance our Alpha implementation.
Further development
The Alpha version of our RAG implementation fits into the paradigm of ”Naive RAG”, and it has its limitations. Notably, the retrieval process is not always successful, leading to situations where the answer is simply “I don’t know.”
To address this, we worked on incorporating advanced RAG techniques with the goal of enhancing our initial “Naive Alpha” version toward an advanced “Beta” release, as represented in figure 3.
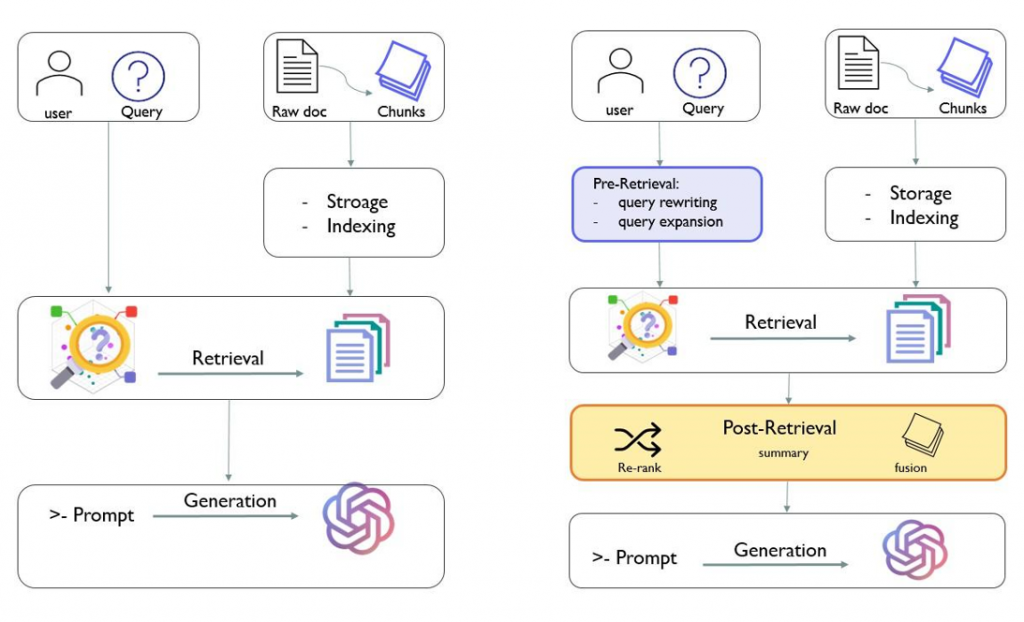
Our focus is on superior query processing, which involves query expansion, re-ranking and fusion.
As figure 4 illustrates, the original query is used to generate more queries, which in turn retrieve various results. These results undergo ranking fusion to produce the final ranking results.
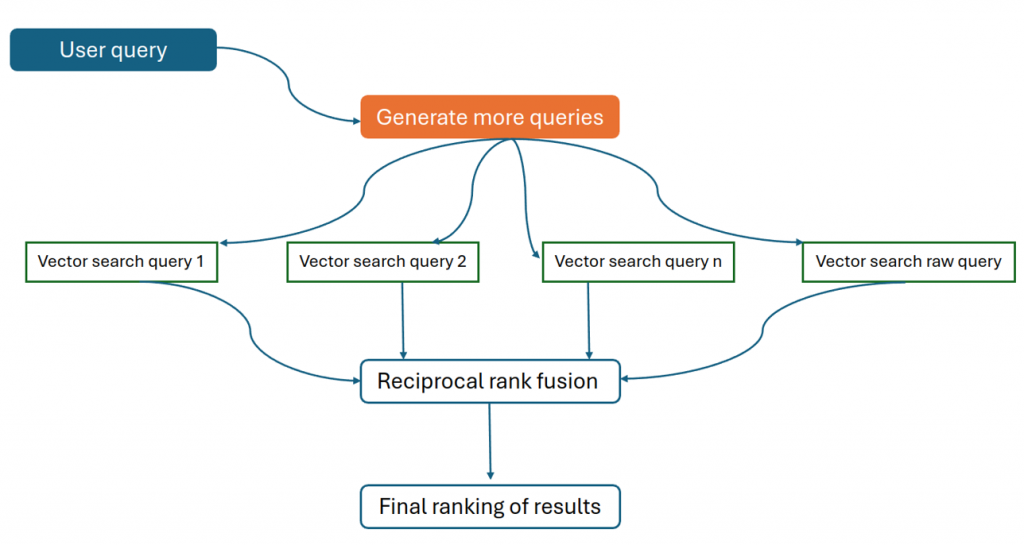
In practice this means that once a user inputs their query, it is passed to an LLM instructed to generate several similar queries that cover the subject of the original query from various perspectives. These generated queries are then given to a search function, and each retrieves potential documents for the answer. The top results are then aggregated and fused to keep the best-scoring and most diverse retrieves, which are used to augment the generation.
Observing the results, we can notice that query expansion enhanced access to a broader range of documents, enriching references for better responses. Additionally, fusion search resulted in higher average rankings compared to the raw user query. The final ranking process does not heavily prioritize frequently occurring documents by giving them more weight. Instead, the primary advantage lies in gathering a diverse set of relevant documents.
The described approach achieved improved retrievals in terms of relevance scoring and diversity, resulting in the generative model being able to answer more of the user’s questions based on the retrieved documents. However, our application still has limitations to further address. During testing of the Beta version, we observed that the generative model excels in answering questions that require extensive responses when provided with multiple sources. However, it struggles with concise queries. Despite being supplied with the answer-containing reference, it occasionally fails to recognize it within the extended context.
This indicates a potential need for proper ReRanker model adjustment, or a more dynamic referencing approach. Further experimentation is needed to identify causes and address them.
Conclusion
Our project work progressed in tandem with the release of recent papers. In several situations, we examined just published papers, contemplating how to translate their ideas into practice. Interestingly, some articles from 2019 and 2021 seemed outdated, given the rapid pace of LLM development. This could be stated as the main challenge faced during the project work.
Nevertheless, we are satisfied with how we implemented the RAG application for 3GPP Cr analytics, bringing it to a production-like setup where it serves as stable technology with a perfectly suitable use case based on manual testing, potential user feedback at Mediatek and the 3GPP delegation, and our steering group feedback.
A significant part of the application’s success is attributed to meticulous data preprocessing steps to ensure that the data is meaningfully digested by the application. Surprisingly, traditional programming remains the backbone of systems incorporating LLMs like RAG. Our open-source-centric approach equipped us with excellent tools without requiring an extensive budget allocation for progress, which increased our solution efficiency.
We are grateful for the experience of pushing the boundaries of technology, enhancing our skills relevance to the latest advancements.
Our RAG application currently runs as a beta version, closely aligned with an advanced RAG paradigm. It has the potential for improving the browsing experience of 3GPP documentation and change requests by incorporating semantic and relational search capabilities. Expanding the application further to include knowledge graphs, and a modular RAG implementation could revolutionize how organizations handle extensive documentation, especially in use cases similar to 3GPP, where dependencies abound.
RAG in general faces a weakness in terms of evaluation frameworks. Metrics such as precision (the accuracy of answers provided by the system) and recall (evaluating the extent of which the retrieval aligns with the expected output) are crucial for assessing these applications. Developing customized RAG evaluation framework specific to the RAG application would address this need.
We thank Mediatek for providing us an interesting topic and guidance in our journey to the more or less uncharted land of LLM AI’s. The results were good and Mediatek steering group was quite satisfied with the results, their comments are included here:
Dear Team,
Here is Our feedback for project combined in couple of sentences! 😄Congratulations on the outstanding success of the RAG application. The dedication and professionalism demonstrated throughout the project have truly shone brightly.
The innovative use of Generative AI has significantly improved our processes and the overall quality of the application. By effectively employing the MVP model and emulating a start-up workflow, the project phases progressed smoothly, resulting in high user satisfaction. Open communication and resource sharing were key to our success, fostering a collaborative environment. Additionally, the focus on market needs and user preferences led to the development of a highly user-friendly and engaging application.
In summary, the hard work and dedication of the team have produced a product that surpasses our initial vision. It has been a privilege to work with such a skilled group.
Kiitos vielä kerran upeasta työstä! Yhteistyö ja sinnikkyys vievät pitkälle.
Moufida Dkhili EP Alakulju
Student in Oulu University of Applied Sciences in Degree Programme in Information Technology
Yinan Li
Student in Oulu University of Applied Sciences in Degree Programme in Information Technology
Antti-Jussi Niku
Student in Oulu University of Applied Sciences in Degree Programme in Information Technology
Lasse Haverinen
Team Leader, Lecturer
Engineering
Oulu University of Applied Sciences
References
[1] Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., & Wang, H. (2023). Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv:2312.10997v5 [cs.CL]. https://doi.org/10.48550/arXiv.2312.10997
[2] Hsia, J., Shaikh, A., Wang, Z., & Neubig, G. (2024). Submitted 14 March 2024. RAGGED: Towards Informed Design of Retrieval Augmented Generation Systems. arXiv:2403.09040v1 [cs.CL]. https://doi.org/10.48550/arXiv.2403.09040
[3] AWS Cloud Computing Concepts Hub. (2024). What Are Embeddings in Machine Learning? Teoksessa Cloud Computing Concepts Hub. https://aws.amazon.com/what-is/embeddings-in-machine-learning/
[4] Barnard, J. (22.12.2023). What is embedding? IBM. https://www.ibm.com/topics/embedding
[5] Ostendorff, M., Blume, T., Ruas, T., Gipp, B., & Rehm, G. (2022) Specialized Document Embeddings for Aspect-based Similarity of Research Papers. arXiv:2203.14541v1 [cs.IR]. https://doi.org/10.48550/arXiv.2203.14541
[6] Milvus. (2024). Homepage. https://milvus.io/
[7] Milvus. (2024). Similarity Metrics. https://milvus.io/docs/metric.md

Vastaa
Sinun täytyy kirjautua sisään kommentoidaksesi.